Abstract
Code reading is one of the most frequent activities in software maintenance; before implementing changes, it is necessary to fully understand source code often written by other developers. Thus, readability is a crucial aspect of source code that might significantly influence program comprehension effort. In general, software readability models take into account only structural aspects of source code, e.g., line length and a number of comments. However, code is a particular form of text; therefore, a code readability model should not ignore the textual aspects of source code encapsulated in identifiers and comments. In this paper, we propose a set of textual features that could be used to measure code readability. We evaluated the proposed textual features on 600 code snippets manually evaluated (in terms of readability) by 5K+ people. The results show that the proposed features complement classic structural features when predicting readability judgments. Consequently, a code readability model based on a richer set of features, including the ones proposed in this paper, achieves a significantly better accuracy as compared to all the state-of-the-art readability models.
Dataset
This dataset contains 200 method from four open source projects, namely:
The methods were manually evaluated by 9 Computer Science studens from The College of William and Mary, Williamsburg, VA (USA). The participants were asked to evaluate the readability of each method using a five-point Likert scale ranging between 1 (very unreadable) and 5 (very readable). We collected the rankings through a web application where participants were able to:- read the method (with syntax highlighting);
- evaluate its readability;
- write comments about the method.
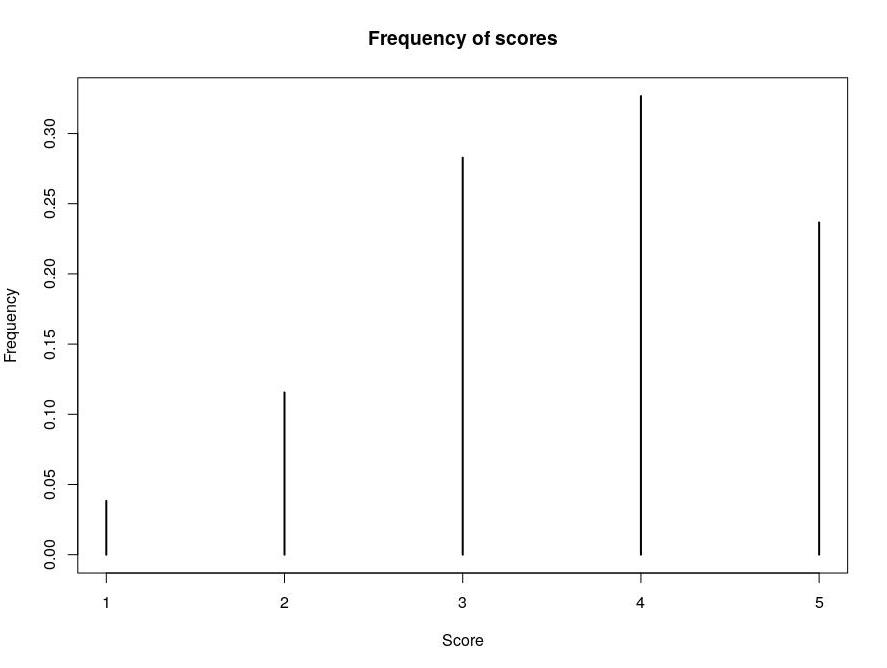
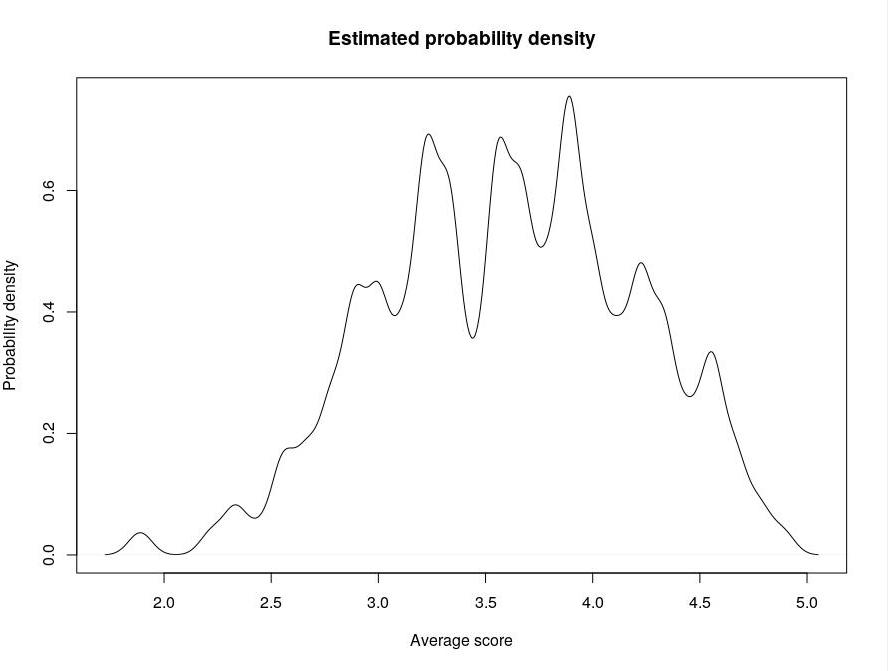
For each single snippet, it was computed the average score, in order to set a proper cut-off to distinguish readable snippets from unreadable ones. The following plots show (i) the frequency of each score and (ii) the (estimated) probability density of the average scores (bandwidth: 0.05):
Material
Extension
Check the extesion of our work: A Comprehensive Model for Code Readability (Online Appendix with the readability tool)